Chapter 6 Case study on acceptability of indicative conditionals
6.1 Theoretical background
Adams famously proposed that the assertability of a conditional sentence \(P \rightarrow Q\) is given by the conditional probability \(P(Q \mid P)\) on some probability distribution representing the uncertainty of the speaker or of the interlocutors’ combined (Adams 1975). Jackson (1987) proposed a reformulation, namely that the acceptability of a conditional \(P \rightarrow Q\) is given by the conditional probability \(P(Q \mid P)\). We call this idea Adams’ thesis (AT).
6.2 “The Adams family”
6.2.1 Design & Materials
Douven and Verbrugge (2010) seek to test Adams’ thesis experimentally. Towards this end, they present participants with 30 vignettes, each containing a context and a conditional statement. Here is one example:
- Context: All students in class 6C have at least a B for their math test paper.
- Statement: If Ben is in class 6C, then he has at least a B for his math test paper.
They then measured, in a between-subjects manipulation spread across three different experiments, how participants rate the statements according to four different kinds of questions, targeted at measuring different theoretical constructs:
- Acceptability: Participants were asked: “How acceptable is this statement in the given context?”
- Reasonable belief: Participants were asked: “How reasonable is it to believe this statement in the given context?”
- Probability of truth of conditional: Participants were asked: “How probable is it that this statement is true in the given context?”
The fourth measure, had a slightly different shape:
- Conditional probability: The context included additionally the clause “Suppose that \(P\) is true.” and the statement to be rated was just the consequent \(Q\). Participants were then asked: “How acceptable is this statement in the given context?”
Of the 30 vignettes, a triplet of 10 vignettes each instantiated one of three types of conditional sentences, namely deductive, inductive and abductive conditionals.
6.2.2 Hypotheses & statistical analyses
Adams’ thesis is interpreted as a statement about the measures of “acceptability” and “conditional probability”. Douven & Verbrugge consider a sequence of ever milder variations on AT, namely:
- AT-strong: \(Ac(P \rightarrow Q) = P(Q \mid P)\)
- AT-approximate: \(Ac(P \rightarrow Q) \approx P(Q \mid P)\)
- AT-categorical: \(Ac(P \rightarrow Q)\) is high/middling/low iff \(P(Q \mid P)\) is high/middling/low
- AT-correlation-strong: \(Ac(P \rightarrow Q)\) highly correlates with \(P(Q \mid P)\)
- AT-correlation-weak: \(Ac(P \rightarrow Q)\) at least moderately correlates with \(P(Q \mid P)\)
We will focus in the following on AT-approximate and AT-correlation-weak .
Moreover, Douven & Verbrugge hypothesize that, according to AT, we would not expect any differences between different types of conditionals.
In sum, we have two main hypotheses, each with a subordinate hypothesis, which the paper addresses as follows with statistical tests:
- H1 :: AT-approximate: There is no difference between ratings given for the “acceptability” and those given for the “conditional probability” condition. The paper tests this in the form of a main effect of GROUP in an ANOVA with factors GROUP (which question was answered) and COND-TYPE (which type of conditional sentence was rated).
- H1-types: Since AT predicts no differences between types of conditionals, there should be no main effect of COND-TYPE or an interaction between GROUP and COND-TYPE.
- H2 :: AT-correlation-weak: There is a positive correlation between average ratings for the “acceptability” ratings and the “conditional probability” ratings (two averaged measures for each of the 30 vignettes, compared against each other). The paper addresses this by a correlation test.
- H2-types: Since AT predicts no differences between types of conditionals, there should be no difference in correlation tests when we look at each type of conditional in isolation.
6.2.3 Results
Douven and Verbrugge (2010) report data that discredits Adams’ thesis, at least under strong and encompassing interpretations. As for H1 and H1-types, they report a main effect of GROUP (rating “acceptability” vs rating “conditional probability”), a significant main effect of COND-TYPE and a significant interaction between the two (their Experiment 1). This result is visually discernible in the plot below, taken from Douven and Verbrugge (2010), where data from ratings of “probability of truth of conditional” (see above) are also plotted.
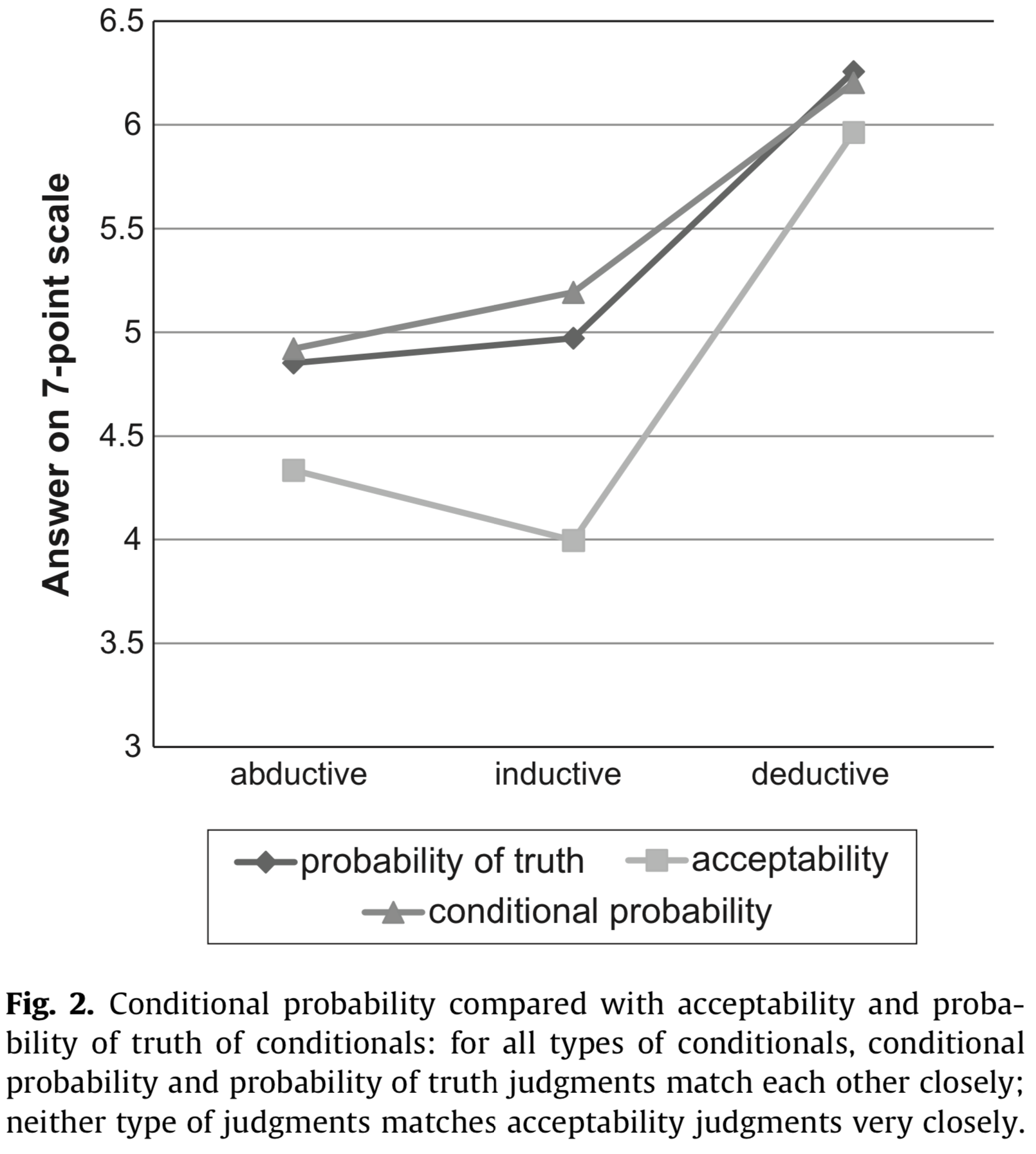
Douven and Verbrugge (2010) also report a significant correlation, in general support of H2, but note that H2-types is cast into doubt because the interaction on the data with only inductive conditions is, though significant, less pronounced (\(R = .65\), compared to \(R = .81\) and \(R = .88\) for abductive and deductive conditionals respectively).
6.3 Replication of Douven and Verbrugge (2010)
6.3.1 Preregistration procedure
Here is the example of the preregistration report discussed in class, together with the pre-registered analysis file and the pilot data. The official preregistration at osf.io can be found here. The experiment can be inspected here.
6.3.2 Results
160 participants were recruited, as planned, via online crowd-sourcing platform Prolific, and were paid 1.5 British pounds for compensation, amounting to an estimated hourly wage of 7.5 pounds.
library(tidyverse)
library(brms)
options(mc.cores = parallel::detectCores())
library(faintr)
# install this package using devtools package:
# devtools::install_github(repo = "michael-franke/bayes_mixed_regression_tutorial",subdir = "faintr")
# see https://psyarxiv.com/cdxv3 for details about the 'faintr' package
######################################
## read and prepare the data
#######################################
d = read_csv('materials/data_raw_final.csv') %>%
# extract information to use for analysis
mutate(
# what was the "rating" / "group" for each participant?
rating = ifelse(stringr::str_detect(optionLeft, "likely"), "cond_probability", "acceptability"),
# what was the conditional-type?
cond_type = factor(condition, levels = c("II", "AI", "DI"), ordered = T),
# consecutively number the items
item_nr = factor(QUD) %>% as.integer() %>% factor()
)
glimpse(d)## Observations: 4,800
## Variables: 24
## $ submission_id <dbl> 8184, 8184, 8184, 8184, 8184, 8184, 8184, 8184, ...
## $ QUD <chr> "<i>Context:</i><br /> The police received an an...
## $ RT <dbl> 36534, 21349, 25535, 23789, 28719, 25116, 16805,...
## $ age <dbl> 43, 43, 43, 43, 43, 43, 43, 43, 43, 43, 43, 43, ...
## $ comments <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, ...
## $ condition <chr> "II", "AI", "AI", "DI", "AI", "DI", "DI", "II", ...
## $ education <chr> "Graduated High School", "Graduated High School"...
## $ endTime <dbl> 1.565795e+12, 1.565795e+12, 1.565795e+12, 1.5657...
## $ experiment_id <dbl> 63, 63, 63, 63, 63, 63, 63, 63, 63, 63, 63, 63, ...
## $ gender <chr> "male", "male", "male", "male", "male", "male", ...
## $ languages <chr> "English", "English", "English", "English", "Eng...
## $ optionLeft <chr> "Highly unacceptable", "Highly unacceptable", "H...
## $ optionRight <chr> "Highly acceptable", "Highly acceptable", "Highl...
## $ prolific_id <chr> "5d11dd0790265e00019ba937", "5d11dd0790265e00019...
## $ question <chr> "<strong>How acceptable is this statement in the...
## $ response <dbl> 6, 6, 7, 6, 3, 7, 7, 4, 3, 6, 1, 1, 6, 4, 1, 4, ...
## $ startDate <chr> "Wed Aug 14 2019 15:45:42 GMT+0100 (British Summ...
## $ startTime <dbl> 1.565794e+12, 1.565794e+12, 1.565794e+12, 1.5657...
## $ timeSpent <dbl> 12.76455, 12.76455, 12.76455, 12.76455, 12.76455...
## $ trial_name <chr> "experiment", "experiment", "experiment", "exper...
## $ trial_number <dbl> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 1...
## $ rating <chr> "acceptability", "acceptability", "acceptability...
## $ cond_type <ord> II, AI, AI, DI, AI, DI, DI, II, AI, DI, II, II, ...
## $ item_nr <fct> 23, 28, 16, 14, 12, 5, 8, 2, 19, 25, 27, 15, 6, ...Following preregistered protocol, we excluded data from all participants and selected trials based on too fast reaction times.
#######################################
## data cleaning, following
## pre-registered exclusion protocol
#######################################
# remove all participants who responded in less than 3
# seconds to more than 2 trials
d = d %>% group_by(submission_id) %>%
mutate(subj_too_fast = sum(RT<3000) > 2) %>%
ungroup()
message("Remove all data from ",
filter(d, subj_too_fast == T) %>% pull(submission_id) %>% unique() %>% length(),
" participants for being too fast on more than 2 trials.")## Remove all data from 7 participants for being too fast on more than 2 trials.d = filter(d, subj_too_fast == F)
# remove all trials faster than 3 seconds
d = d %>%
mutate(trial_too_fast = RT < 3000)
message("Remove data from ",
filter(d, trial_too_fast == T) %>% nrow(),
" trials for being too fast.")## Remove data from 38 trials for being too fast.We can plot the average data similar for visual inspection in parallel to the above figure from the original paper:
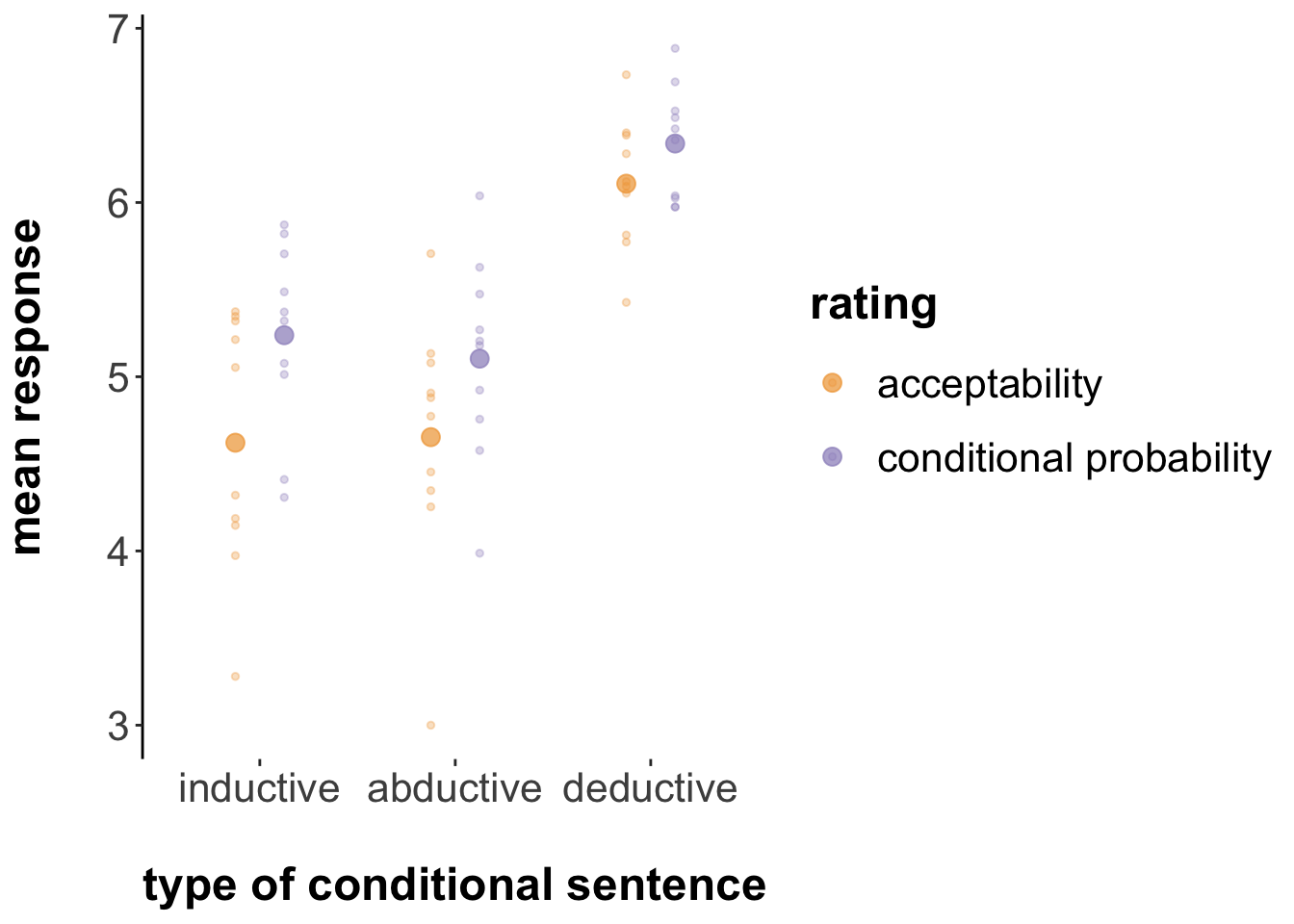
The plot shows the means of the given ratings (we (hesitantly) follow the original paper in assuming that taking means is legitimate for this ordinal measure) for each relevant condition in the bigger dots, together with the means for each individual test sentence in the smaller dots. The latter showcases partly the variability in the given ratings.
Visually, it appears that ratings of “acceptability” are always tendetially lower, on average, that ratings of “conditional probability”, irrespective of the conditional type, although this (visual!) effect seems smaller in case of deductive conditionals.
6.3.3 Analyses for H1
We address H1 with a Bayesian linear hierarchical model:
#######################################
## H1: (near-)identity reading of AT
#######################################
fit_h1 = brm(
formula = response ~ rating * cond_type +
(1 | submission_id + item_nr),
data = d %>% mutate(cond_type = case_when(condition == "AI" ~ "x_AI",
condition == "II" ~ "x_II",
TRUE ~ "DI")),
prior = c(prior(normal(0, 10), class = b))
)To test H1, we are interested in a main effect of the RATING manipulation:
# check for main effect of RATING factor
faintr::compare_groups(
model = fit_h1,
lower = list(rating = "acceptability"),
higher = list(rating = "cond_probability")
)## Outcome of comparing groups:
## * higher: rating:cond_probability
## * lower: rating:acceptability
## Mean 'higher - lower': 0.4378
## 95% CI: [ 0.2665 ; 0.6246 ]
## P('higher - lower' > 0): 1This result tells us that our posterior belief, given model and data, that the ratings of “conditional probability” are higher should be approximately 1 (after numerical rounding).
We compare the posteriors on estimated means also for each type of conditional individually:
# deductive
faintr::compare_groups(
model = fit_h1,
lower = list(rating = "acceptability", cond_type = "DI"),
higher = list(rating = "cond_probability", cond_type = "DI")
)## Outcome of comparing groups:
## * higher: rating:cond_probability cond_type:DI
## * lower: rating:acceptability cond_type:DI
## Mean 'higher - lower': 0.2351
## 95% CI: [ 0.01332 ; 0.4224 ]
## P('higher - lower' > 0): 0.9878# abductive
faintr::compare_groups(
model = fit_h1,
lower = list(rating = "acceptability", cond_type = "x_AI"),
higher = list(rating = "cond_probability", cond_type = "x_AI")
)## Outcome of comparing groups:
## * higher: rating:cond_probability cond_type:x_AI
## * lower: rating:acceptability cond_type:x_AI
## Mean 'higher - lower': 0.4552
## 95% CI: [ 0.2465 ; 0.6431 ]
## P('higher - lower' > 0): 1# inductive
faintr::compare_groups(
model = fit_h1,
lower = list(rating = "acceptability", cond_type = "x_II"),
higher = list(rating = "cond_probability", cond_type = "x_II")
)## Outcome of comparing groups:
## * higher: rating:cond_probability cond_type:x_II
## * lower: rating:acceptability cond_type:x_II
## Mean 'higher - lower': 0.6232
## 95% CI: [ 0.418 ; 0.8159 ]
## P('higher - lower' > 0): 1These results suggest that for all types of conditional sentences, ratings of “conditional probability” were credibly larger that those of “acceptability”.
6.3.4 Analyses for H2
We first aggregate the data, looking at the average ratings for each sentence for each type of RATING.
# correlation analysis
d_cor = d %>% group_by(item_nr, cond_type, rating) %>%
summarize(response = mean(response)) %>%
spread(key = "rating", value = "response") %>%
ungroup()
# plot the correlation
d_cor %>% ggplot(aes(x = acceptability, y = cond_probability, color = cond_type)) +
geom_point() + geom_smooth(method = "lm")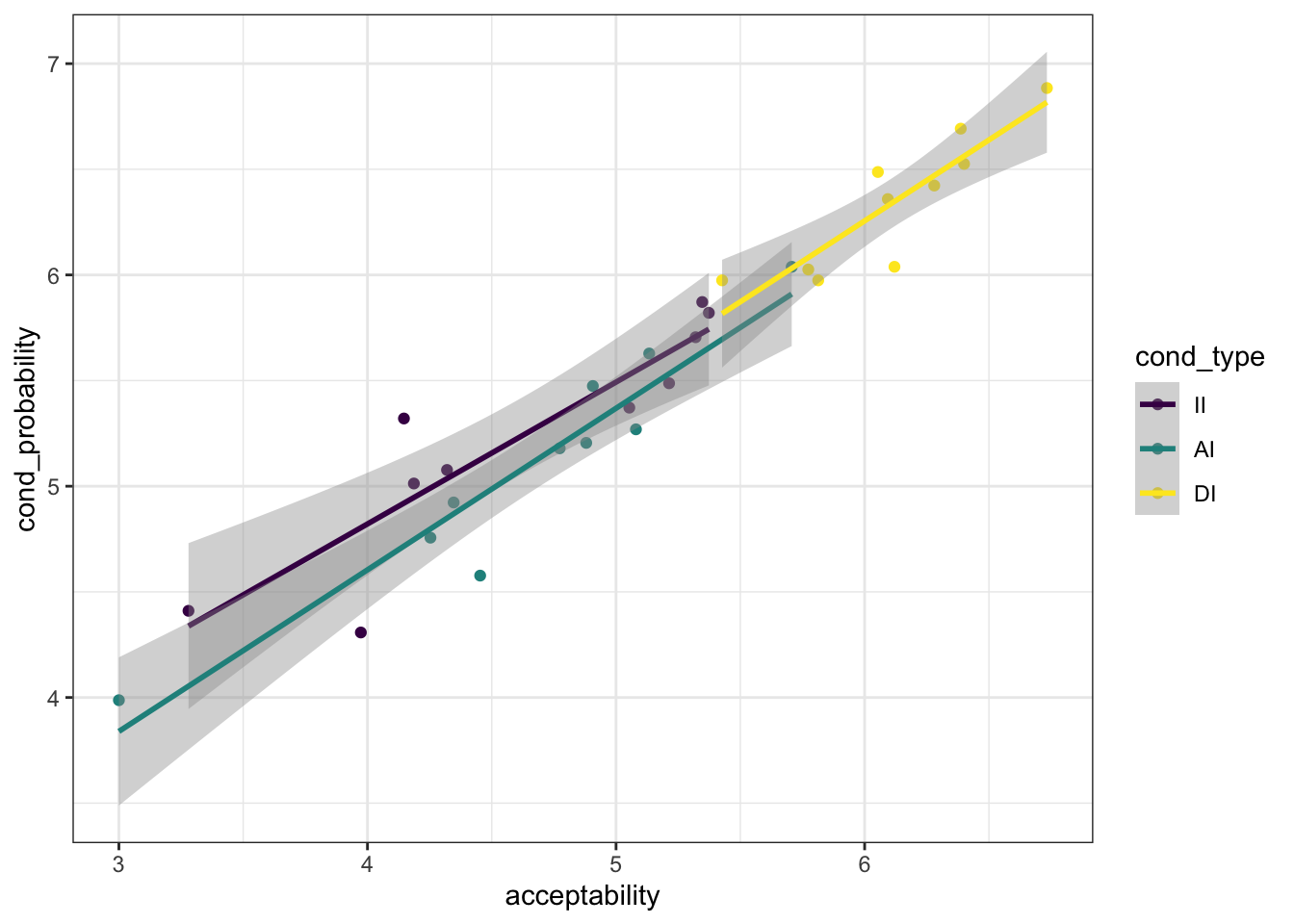
To test whether there is, in general, a positive correlation between “acceptability” and “conditional probability” ratings for each sentence, we run a linear regression model based on all data first:
# all data
fit_h2 = brm(
formula = acceptability ~ cond_probability,
data = d_cor,
prior = c(prior(normal(0, 10), class = b),
prior(normal(1, 10), coef = "cond_probability"))
)## Family: gaussian
## Links: mu = identity; sigma = identity
## Formula: acceptability ~ cond_probability
## Data: d_cor (Number of observations: 30)
## Samples: 4 chains, each with iter = 2000; warmup = 1000; thin = 1;
## total post-warmup samples = 4000
##
## Population-Level Effects:
## Estimate Est.Error l-95% CI u-95% CI Eff.Sample Rhat
## Intercept -1.64 0.37 -2.38 -0.90 3495 1.00
## cond_probability 1.22 0.07 1.09 1.35 3541 1.00
##
## Family Specific Parameters:
## Estimate Est.Error l-95% CI u-95% CI Eff.Sample Rhat
## sigma 0.27 0.04 0.21 0.35 2621 1.00
##
## Samples were drawn using sampling(NUTS). For each parameter, Eff.Sample
## is a crude measure of effective sample size, and Rhat is the potential
## scale reduction factor on split chains (at convergence, Rhat = 1).We find a 95% credible interval for the slope coefficient (called cond_probability in the summary table) with a lower bound of 1.09, suggesting clearly a positive overall correlation.
To test H2-types, we look at the data from each type of conditional sentence separatedly.
# deductive conditionals
fit_h2_type_DI = brm(
formula = acceptability ~ cond_probability,
data = d_cor %>% filter(cond_type == "DI"),
prior = c(prior(normal(0, 10), class = b),
prior(normal(1, 10), coef = "cond_probability"))
)## Family: gaussian
## Links: mu = identity; sigma = identity
## Formula: acceptability ~ cond_probability
## Data: d_cor %>% filter(cond_type == "DI") (Number of observations: 10)
## Samples: 4 chains, each with iter = 2000; warmup = 1000; thin = 1;
## total post-warmup samples = 4000
##
## Population-Level Effects:
## Estimate Est.Error l-95% CI u-95% CI Eff.Sample Rhat
## Intercept -0.34 1.52 -3.32 2.69 2221 1.00
## cond_probability 1.02 0.24 0.54 1.49 2224 1.00
##
## Family Specific Parameters:
## Estimate Est.Error l-95% CI u-95% CI Eff.Sample Rhat
## sigma 0.22 0.07 0.13 0.40 1603 1.00
##
## Samples were drawn using sampling(NUTS). For each parameter, Eff.Sample
## is a crude measure of effective sample size, and Rhat is the potential
## scale reduction factor on split chains (at convergence, Rhat = 1).# abuctive conditionals
fit_h2_type_AI = brm(
formula = acceptability ~ cond_probability,
data = d_cor %>% filter(cond_type == "AI"),
prior = c(prior(normal(0, 10), class = b),
prior(normal(1, 10), coef = "cond_probability"))
)## Family: gaussian
## Links: mu = identity; sigma = identity
## Formula: acceptability ~ cond_probability
## Data: d_cor %>% filter(cond_type == "AI") (Number of observations: 10)
## Samples: 4 chains, each with iter = 2000; warmup = 1000; thin = 1;
## total post-warmup samples = 4000
##
## Population-Level Effects:
## Estimate Est.Error l-95% CI u-95% CI Eff.Sample Rhat
## Intercept -1.42 0.90 -3.21 0.33 2131 1.00
## cond_probability 1.19 0.17 0.85 1.53 2167 1.00
##
## Family Specific Parameters:
## Estimate Est.Error l-95% CI u-95% CI Eff.Sample Rhat
## sigma 0.28 0.09 0.16 0.52 1848 1.00
##
## Samples were drawn using sampling(NUTS). For each parameter, Eff.Sample
## is a crude measure of effective sample size, and Rhat is the potential
## scale reduction factor on split chains (at convergence, Rhat = 1).# inductive conditionals
fit_h2_type_II = brm(
formula = acceptability ~ cond_probability,
data = d_cor %>% filter(cond_type == "II"),
prior = c(prior(normal(0, 10), class = b),
prior(normal(1, 10), coef = "cond_probability"))
)## Family: gaussian
## Links: mu = identity; sigma = identity
## Formula: acceptability ~ cond_probability
## Data: d_cor %>% filter(cond_type == "II") (Number of observations: 10)
## Samples: 4 chains, each with iter = 2000; warmup = 1000; thin = 1;
## total post-warmup samples = 4000
##
## Population-Level Effects:
## Estimate Est.Error l-95% CI u-95% CI Eff.Sample Rhat
## Intercept -1.76 1.34 -4.38 0.94 2509 1.00
## cond_probability 1.22 0.25 0.70 1.71 2538 1.00
##
## Family Specific Parameters:
## Estimate Est.Error l-95% CI u-95% CI Eff.Sample Rhat
## sigma 0.40 0.13 0.23 0.73 1801 1.00
##
## Samples were drawn using sampling(NUTS). For each parameter, Eff.Sample
## is a crude measure of effective sample size, and Rhat is the potential
## scale reduction factor on split chains (at convergence, Rhat = 1).In sum, there does seem to be evidence that for all types of conditionals, a positive correlation holds between ratings of “acceptability” and “conditional probability”.
6.3.5 Conclusions
The main findings of the Douven and Verbrugge (2010) were replicated: ratings of “acceptability” and “conditional probability” seem to differ, and there does seem to be a general positive correlation between the two (based on averages of ratings per item).
However, unlike Douven and Verbrugge (2010), we do not a strong basis to conclude that different types of conditional sentences (abductive, inductive and deductive) behave (qualitatively) any differently from each other. We note that ratings for the deductive conoditionals were higher in general, and that this could also have affected the size of the difference (a ceiling effect).
References
Adams, E. W. 1975. The Logic of Conditionals. Dordrecht: Elsevier.
Douven, Igor, and Sara Verbrugge. 2010. “The Adams Family.” Cognition 117: 302–18. https://doi.org/10.1016/j.cognition.2010.08.015.
Jackson, F. 1987. Conditionals. Oxford: Blackwell.